You can't just tell an LLM to write Domo API functions and expect useful output. The model has never seen your internal SDK, your auth patterns, or your naming conventions — so it guesses wrong, every time.
Why It Matters
LLMs are pattern-completion engines, not knowledge bases. If you want a model to generate code that fits your codebase, you have to teach it what your code looks like — not by fine-tuning, but by showing it examples at prompt time. Without this, you get syntactically plausible code that breaks your conventions, uses the wrong auth object, and has to be rewritten anyway. With it, you get a code generator that writes in your style: snake_case, your specific API client, your parameter patterns. This is what unlocks AI as an actual productivity tool rather than a novelty.
What You'll Learn
- Understand why LLMs fail to generate useful Domo API code without code samples in the prompt
- Build a prompt strategy that encodes your personal coding conventions (naming, auth, structure)
- Provide in-context examples so the model mimics your style rather than inventing its own
- Generate new Domo API functions (e.g., updating dataflow tags and descriptions) without writing them from scratch
- Distinguish between fine-tuning and few-shot prompting as strategies for style-aware code generation
Teaching an LLM to Write Your Code, Not Its Own
The core insight here is that LLMs don't learn — they pattern-match. When you ask GPT to write a function that updates Domo dataflow tags, it has no idea what your auth object looks like, that you use client.get_data_sync to send API requests, or that you'd rather delete your keyboard than write camelCase. It will produce something plausible and wrong.
The fix is to stop treating the model as a knowledge source and start treating it as a style mimic. Before asking it to write new code, you hand it existing functions you've written — your real, working Domo SDK code — and instruct it: this is how functions are structured here. The model picks up that O objects carry the Domo instance, that auth flows through a specific pattern, that snake_case is non-negotiable.
This is few-shot prompting applied to code generation, and it works because the model's job is now well-defined: extend this pattern, don't invent a new one.
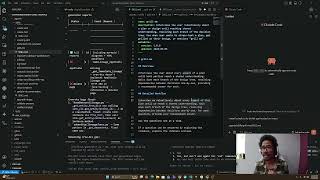
In practice, this means the prompt includes:
- 2-3 example functions that represent your style (e.g.,
get_dataflow_by_id,get_dataflow_definition) - Explicit style rules ("always snake_case", "use
client.get_data_syncfor HTTP calls") - The specific task: write a
update_dataflow_tagsfunction following the same structure
The result isn't magic — it's a model that has been given enough signal to guess the right next tokens. The output still needs review, but it's reviewing code written in your voice rather than rewriting code from scratch.
This matters most when your SDK or internal library isn't publicly documented. If it's not on the internet, the base model doesn't know it exists. Your examples are the training data.